Pandas
- 표 형식의 데이터나 다양한 형태의 데이터를 다룸
- 시리즈(Series) 클래스와 데이터프레임(DataFrame) 클래스를 제공
Series
- 일련의 객체를 담을 수 있는 1차원 배열 같은 자료구조.
- 1치원 배열과 달리 값뿐만 아니라 각 값에 연결된 인덱스 값도 동시에 저장.
- 시리즈 객체는 라벨 값에 의해 인덱싱 가능하므로 인덱스 라벨 값을 키로 갖는 딕셔너리 자료형과 같다고 볼 수 있음.(in, items, key와 value 접근)

pandas.Series( data,
index,
dtype,
copy)| data | series를 구성할 데이터 |
| index | index 지정. |
| dtype | 각 항목에 적용될 타입. |
- Series.values : Series 값 추출.
- Series.index : index 값 추출.
- Series.reindex: 값 재배열, 없는 인덱스는 NaN으로 나옴.
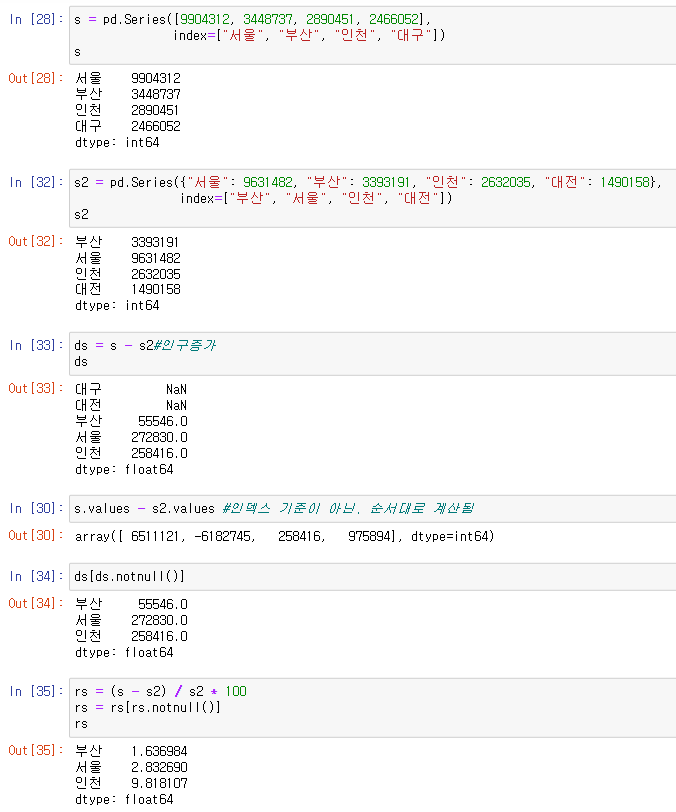
Series. index 값 연산
Series는 [ ] 안에 조건을 넣어 값 추출 가능!
Series는 값을 추출해서 연산을 하지 않고 → Series 앞에 바로 연산 가능.
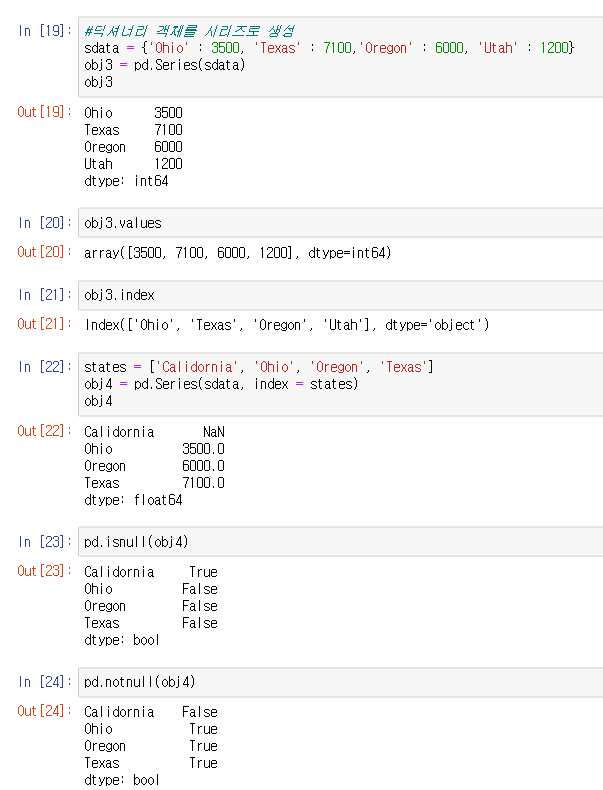
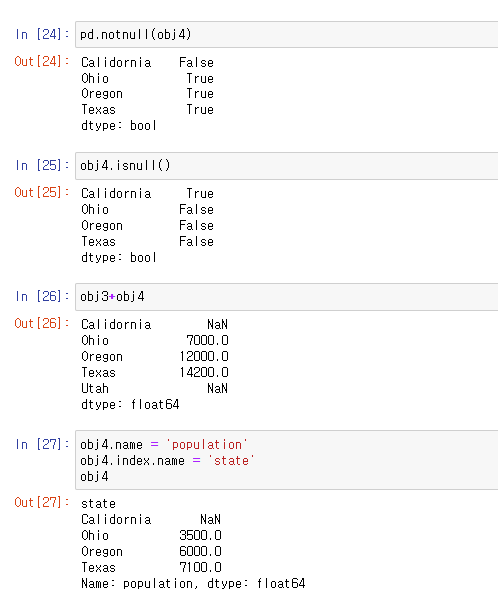
딕셔너리 객체를 Series로 변경
Series Indexing
Series 객체를 Indexing 하는 방법.

- 숫자 인덱싱: [ 0 : 2 ] → 0에서 1까지 값 추출.
- 문자 인덱싱: [ "부산" : "대구" ] → 대구 인덱싱도 포함된 값 추출.
Series 데이터 갱신, 추가, 삭제
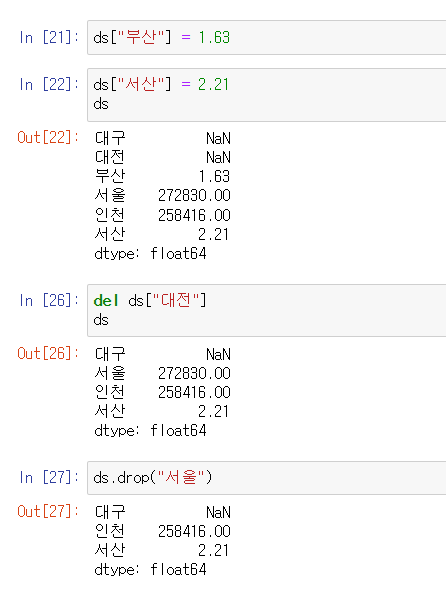
< 수정 >
"부산" 인덱스 데이터가 이미 존재할 때는
ds [ "부산" ] = 1.63
하면 값을 수정해준다!
< 추가 >
서산 인덱스는 존재하지 않기 때문에
ds [ "서산" ] = 2.21
을 입력하면 새로 인덱스를 추가해준다!
< 삭제 >
삭제 - del, drop
→ del ds [ "대전" ]
→ ds.drop( "서울" )
DataFrame
- 표 같은 스프레드시트 형식의 자료구조 - 각 칼럼은 다른 종류의 값을 담을 수 있음.
- DataFrame은 Row, Column, Series 들로 구성되어있음. (Series는 각 Column에 있는 데이터)
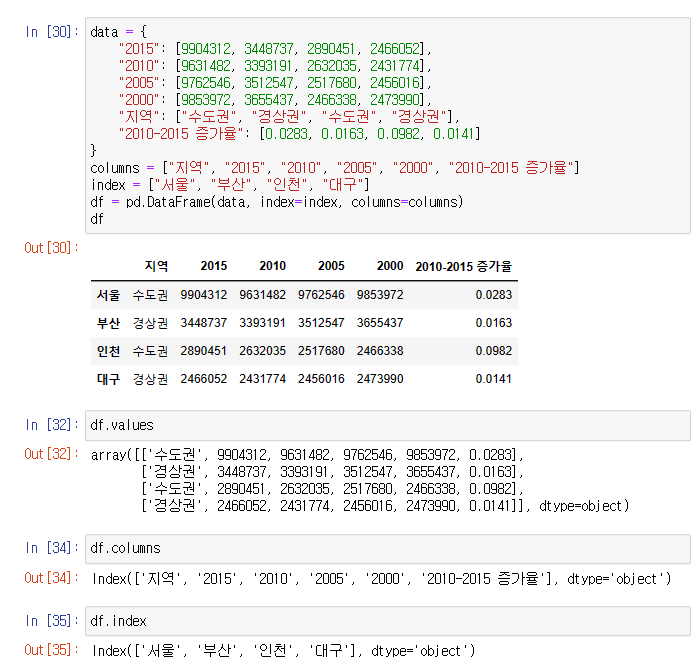
import pandas as pd
df = pd.DataFrame(data,
index = "",
columns = "",
dtype = "",
copy = "")| data | DataFrame을 생성할 데이터 |
| index | 각 Row에 대해 Label을 추가 (옵션) |
| coulumns | 각 Column에 대해 Label을 추가 (옵션) |
| dtype | dtype - 각 Column의 데이터 타입 명시 (옵션) |
- DataFrame.values : dataframe에 들어있는 값 추출
- DataFrame.columns: dataframe에 들어있는 열 칼럼 추출.
- DataFrame.index: dataframe에 들어있는 인덱스 값 추출.
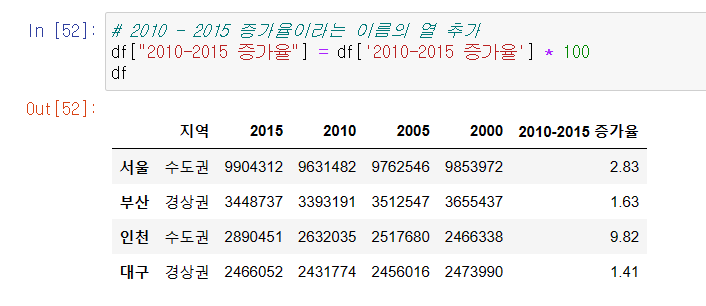
열 데이터 추가, 수정, 삭제
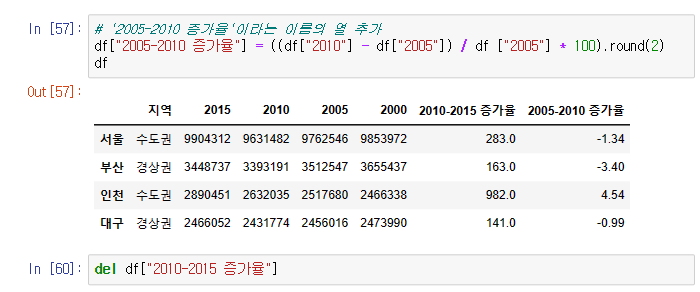
열 인덱싱

- 열 데이터프레임의 열 인덱스가 문자열 라벨을 가지고 있는 경우에는 순서를 나타내는 정수 인덱스를 열 인덱싱에 사용할 수 없음.
- 원래부터 문자열이 아닌 정수형 열 인덱스를 가지는 경우에는 인덱스 값으로 정수를 사용할 수 있음.
행 인덱싱
행 단위로 인덱싱을 하고자 하면 항상 슬라이싱(slicing)을 해야 한다.

데이터 입출력
| read_csv | csv 파일을 가져오는 함수 (구분자는 쉼표 [ , ]) |
| read_table | table 파일을 가져오는 함수 (구분자는 탭 [ \t ]) |
| read_fwf | 고정폭 (구분자 없음) |
| read_clipboand | 클립보드, 웹 페이지의 표 읽어올 때 사용 |
| read_excel | 엑셀 파일에서 표 형식 데이터 읽기 |
| read_hdf | HDFS 파일에서 데이터 읽기 |
| read_html | HTML 문서 내의 모든 테이블 |
| read_json | Json 문자열에서 데이터 읽기 |
- read_csv
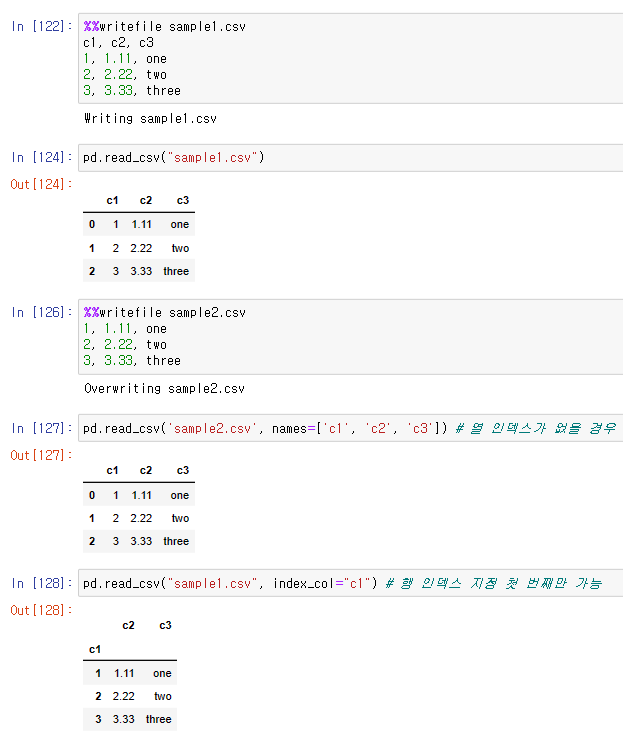
# CSV 파일 생성하기
%%writefile sample1.csv
c1, c2, c3
1, 1.11, one
2, 2.22, two
3, 3.33, three%% : 매직라인 (빈번하게 쓰는 것을 정리하는 것

- read_table
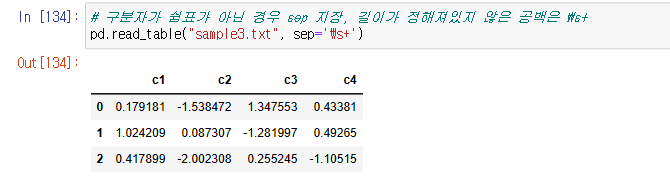
%%writefile sample3.txt
c1 c2 c3 c4
0.179181 -1.538472 1.347553 0.43381
1.024209 0.087307 -1.281997 0.49265
0.417899 -2.002308 0.255245 -1.10515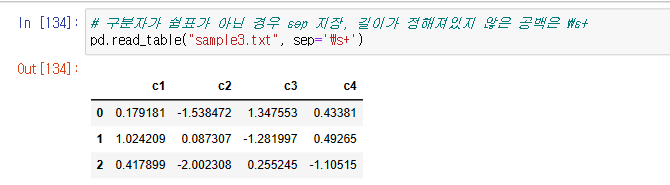
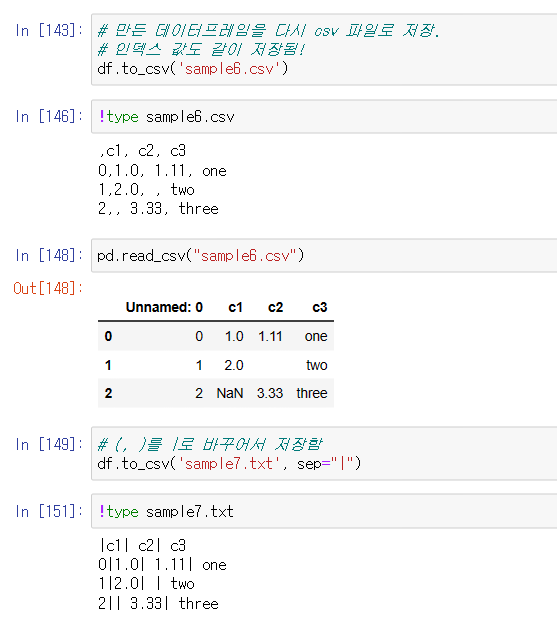
파일 저장, 출력
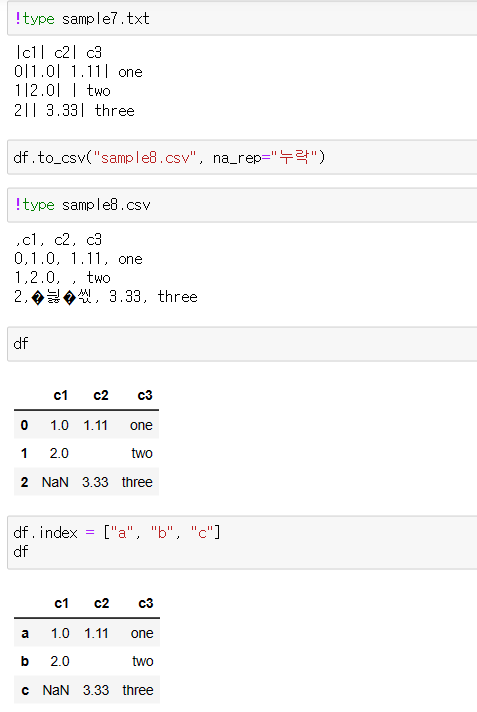
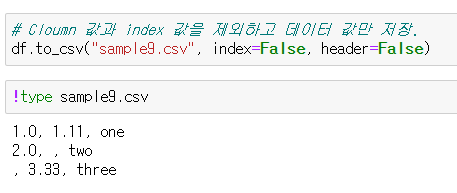
행, 열 조회하기
- 행을 조회하기 위한 행명(인덱스명) 입력
- 배열 형태가 아닌 값을 입력하면 1차원 시리즈 형태가 리턴!
| 속성 | 설명 |
| loc | 인덱스 기준으로 행 데이터 읽기 |
| iloc | 행 번호를 기준으로 행 데이터 읽기 |
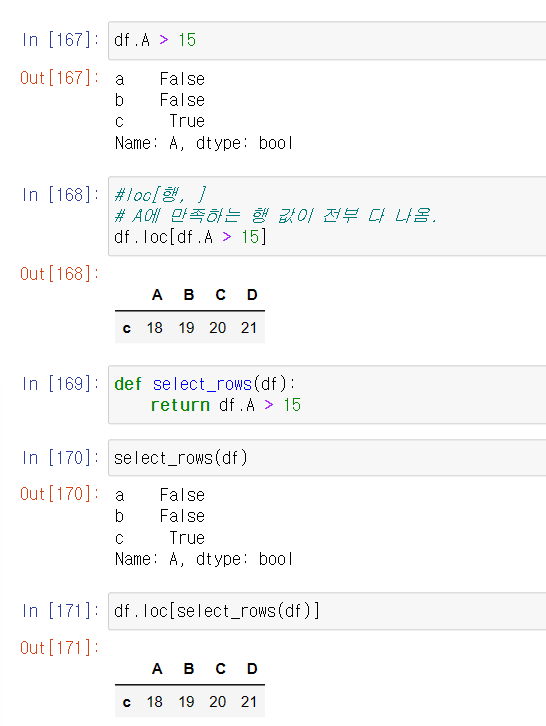
행 조회하기 - loc( )
| 함수 | 설명 |
| df.loc [ "행 인덱싱 명" ] | 1차원 시리즈 형식으로 값 리턴 |
| df.loc [ [ "행 인덱싱 명" ] ] | 2차원 데이터프레임 형식으로 값 리턴 |
| df.loc [ [ '행 인덱싱 명', '행 인덱싱 명' ] ] | 여러 (인덱스 명)을 입력하여 여러 행을 가져올 수 있음. |
| df.loc [ "행 인덱싱 명" : "행 인덱싱 명" ] | 연속적인 행 가져오기 ex) a 행부터 ~ c행까지 |
| df.loc [ [ True, False ... ] ] (blooean) | 인덱스 개수와 동일한 True/False의 배열을 지정해 True인 행만 가져올 수 있음. |
*df → 데이터프레임 명

열 조회하기 - loc( )
| 함수 | 설명 |
| df.loc [ :, "열 인덱스 명" ] | 해당 열만 가져옴. → 1차원 Series 값으로 가져옴. |
| df.loc [ :, [ "열 인덱스 명" ] ] | 해당 열만 가져옴. → 배열 형태로 열을 입력하면 2차원 Dataframe 형태로 가져옴. |
| df.loc [ :, df.columns != '열 인덱스명' ] | 특정 컬럼을 제외하고 값을 가져옴. |
| df.loc [ : , "행 인덱싱 명" : "행 인덱싱 명" ] | 행 인덱싱 명 ~ 행 인덱싱 명까지의 값을 가져옴. |
| df.loc [ :, [ False, True, True ] ] | 인덱스 개수와 동일한 True/False의 배열을 지정해 True인 행만 가져올 수 있음. |

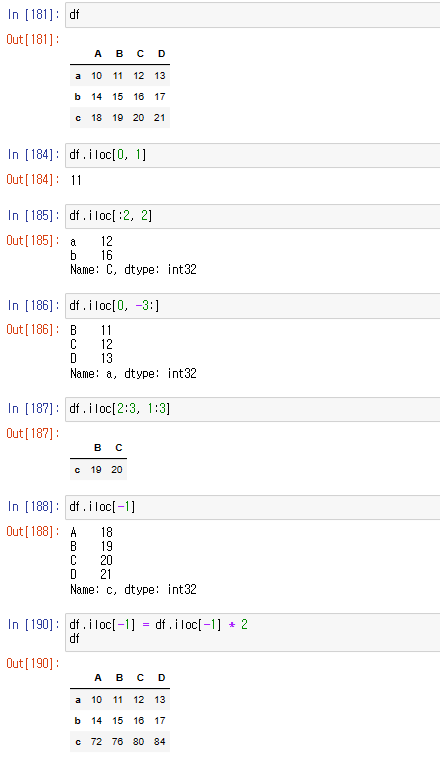
+ iloc ( )
- 인덱스 위치 값으로 데이터 추출
- 순서를 나타내는 정수 기반의 2차원 인덱싱
'ABC 부트캠프 > 파이썬 라이브러리' 카테고리의 다른 글
| 10일차 - Matplotlib, Seaborn (0) | 2023.04.10 |
|---|---|
| 9일차 - Pandas 2 (0) | 2023.04.02 |
| 7일차 - Numpy 2 (0) | 2023.03.23 |
| 6일차 - Numpy 1 (0) | 2023.03.21 |




댓글