아나콘다 설치하기

주피터 노트북 실행하기
셀 사이에 주석 대신 텍스트로 입력 가능.
Cell → Cell Type → Markdown
NumPy(Numerical Python)
- 제공
- 빠르고 효율적인 다차원 배열 객체 ndarray
- 배열 원소를 다루거나 배열 간의 수학 계산을 수행하는 함수
- 디스크로부터 배열 기반의 데이터를 읽거나 쓸 수 있는 도구
- 선형대수 계산, 푸리에 변환, 난수 생성기
- 파이썬 확장과 C, C++ 코드에서 NumPy 의 자료 구조에 접근할 수 있음
- 대용량 데이터 배열을 효율적으로 다룰 수 있음.
- 내부적으로 데이터를 다른 내장 파이썬 객체와 분리된 연속된 메모리 블록에 저장
- 내장 파이썬의 연속된 자료형들보다 더 적은 메모리 사용
- 파이썬 반복문을 사용하지 않고 전체 배열의 복잡한 계산 수행
- 배열에 가지고 있는 것을 사용하기 위한 라이브러리.
- Numpy는 배열이 가장 중요함!
import numpy as np
my_arr = np.arange(1000000)
my_list = list(range(1000000))np.arange( ) → 배열 타입으로 가져옴
list(range( )) → 리스트 타입으로 가져옴.
두 코드로 for문을 돌렸을 때 실행 속도에 차이를 확인할 수 있다.
my_arr 는 배열 타입
my_list 는 리스트 타입
배열 타입이 대용량 데이터를 처리할 때 가장 효율적인 방법!
배열의 연산처리
- list와 차이점
- list는 여러 타입을 지원하지만 ndarray는 하나의 데이터 타입만 가능 → 그래서 연산이 빠르다!
- ndarray는 알아서 하나의 타입으로 형변환
- C의 array와 동일
- 생성하기
- np.array함수를 이용하여 ndarray 형태로 변환
- a = [1,2,3,4,5] ← 리스트 형태
- a_ndarray = np.array(a, int)
- 파이썬은 배열 자료형을 제공하지 않으므로 배열의 표준 패키지는 numpy이며 배열 자료구조 ndarray를 제공함
- 벡터화 연산을 통해 간단한 코드로 복잡한 선형대수 연산
- a_ndarray.shape #크기반환
- a_ndarray.dtype #타입반환
- a_ndarray.ndim #몇 차원인지 반환
- 소수점까지 있어야 정확한 Y값을 예측가능하므로 float사용
- a_ndarray = np.array(a, dtype = np.float32)
*백터화 연산: 행, 열 연산을 의미
[ 1, 2 [ 1, 1 [ 2, 3
3, 4 + 1, 1 4, 5
5, 6 ] 1, 1 ] 6, 7 ]

data * 10을 실행했을 때 그 값은 data에 들어가지 않음.
data * 10 데이터를 저장하고 싶을 때는 다른 배열에 저장해주어야 함.
ex) data1 = data * 10

리스트를 배열로 선언
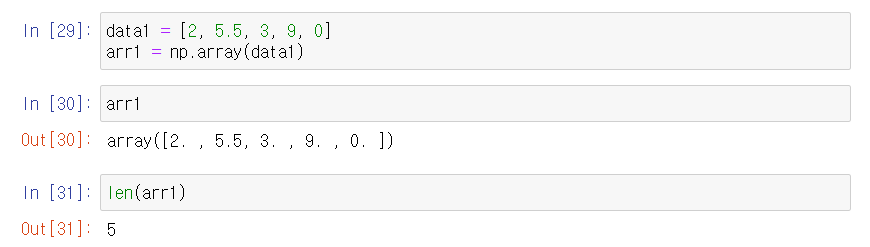

data1의 리스트를 arr1 배열로 바꾸는 과정이다.
arr1로 바꿀 때 타입(int, ...)으로 선언을 하지 않으면 디폴트 값 → float
배열을 int형으로 선언하려면 np.array(data1, int)로 선언해주면 됨!
배열의 차원

배열은 어느 위치를 가르키는지, 그 위치에서 배열을 추출하는 것이 중요함
array 생성
zeros : 0으로 가득찬 array 생성

ones : 1로 가득찬 array 생성

empty : 초기화되지 않은 값으로 생성

something(ones, zeros...)_like : _like는 지정된 array의 shape 크기만큼 지정된 값으로 채워 array 반환

range() 와 numpy.arrange()의 차이
- range(10) : 파이썬 함수로 정수를 리스트로 반환
- np.arange(1,10,0.5) : 정수, 실수를 배열로 반환
- 데이터 분석을 할 때는 실수값으로 많이 분석을 함! -> 실수로 이용을 하는 경우 실수값으로 지정

백터화 연산
배열의 원소에 대한 반복연산을 하나의 명령어로 처리

파이썬에서 배열을 쓰지 않을 때는 for문으로 각각 값을 처리해야 했다. → 백터로 하면 더욱 편하게 할 수 있음.

배열 x, 리스트 data를 비교했을 때
x * 2 했을 때는 배열의 값이 *2씩 증가했지만
data * 2 했을 때는 리스트가 2개 만들어지는 차이점이 있다.

배열에 조건을 주어 비교할 수 있다.

인덱싱, 슬라이싱
인덱싱
내가 원하는 값을 가리킬 때 사용함.
인덱스 값은 0부터 시작한다,
arr[5:8] index 5~7까지의 정보

슬라이싱
무언가를 자른다는 의미로 (리스트, 튜플, 문자열 등)에 부여된 번호를 이용해 연속된 객체에 일부를 추출

arr_slice를 했을 때 데이터를 새롭게 자르는 것이 아닌 일부를 추출해서 가르키는 것.
copy() : 데이터를 복사할 때 사용하는 함수.

slice를 해도 내가 원하는 데이터만 남지 않기 때문에 slice를 한 데이터를 copy() 함수로 사용하여 데이터를 추출한다.
copy() 함수를 사용하면 원본의 함수에 영향이 가지 않음.
배열 값 넣기
arr3d = np.array([[[1, 2, 3],[4, 5, 6]],[[7, 8, 9], [10, 11, 12]]])
arr2d = np.array([[1, 2, 3], [4, 5, 6],[7, 8, 9]])

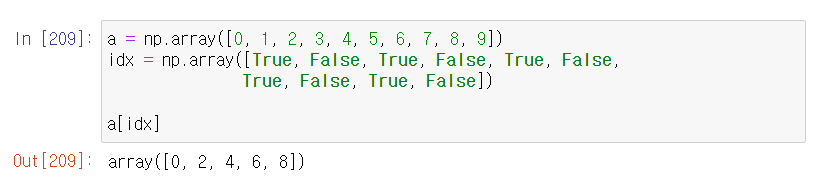
불리언값으로 선택하기
- 인덱스 배열의 원소가 True, False로 이루어짐
- 배열의 크기가 원래 ndarray 객체 크기와 같아야함
a= np.array([0,1,2,3,4,5,6,7,8,9])
idx = np.array([True, False,True, False,True, False,
True, False,True, False])
a[idx]boolean 값으로 인덱스 위치에 True, False 값을 줘서 데이터를 가져오는 여부를 지정할 수 있음.
a 배열과 true, false 값이 담긴 인덱스 배열을 넣어 true에 해당되는 인덱스 값만 추출.
조건에 맞는 값을 가져오고 싶을 때 사용.
ex) 안에 들어있는 값이 짝수인지 알고 싶을 때,

조건에 따라 True, False 값이 나옴.

True, False 값으로 내가 원하는 조건의 인덱스 데이터를 가져올 수 있음.

names 배열에 'bob'과 같은 데이터가 있으면 True를 나타낸다.
data[name == 'bob'] → 이 조건을 주게 된다면
data는 7개의 행을 가지고 있으며, names 배열의 조건 또한 7개이기 때문에
True로 되어있는 인덱스 위치의 data 값을 가져올 수 있다.
또한, 아래처럼 조건을 2개씩 지정할 수 있음.

'ABC 부트캠프 > 파이썬 라이브러리' 카테고리의 다른 글
| 10일차 - Matplotlib, Seaborn (0) | 2023.04.10 |
|---|---|
| 9일차 - Pandas 2 (0) | 2023.04.02 |
| 8일차 - Pandas 1 (0) | 2023.03.27 |
| 7일차 - Numpy 2 (0) | 2023.03.23 |




댓글